




The use of cron jobs is widespread in software applications. These are scheduled tasks that run automatically at specified intervals, ensuring that periodic processes such as sending reports, cleaning up databases, and many others are carried out efficiently. However, as the scale of modern applications grows, the traditional method of implementing cron jobs can become inadequate.
Traditional Cron Jobs: The Limitations
Traditionally, cron jobs have been executed on single machines, often relying on the Linux cron daemon or using platform-specific scheduling libraries or modules. This method is straightforward, and for many applications, entirely sufficient.
However, when we begin to consider applications at scale, several challenges emerge:
Single Point of Failure: A solitary machine or process means that if anything goes wrong (hardware failure, software crash, etc.), the entire scheduled task system can go down.
Resource Limitations: As the volume of tasks grows, a single machine may not have sufficient resources (CPU, memory, or I/O) to handle the load, leading to missed tasks or severe lag.
Lack of Redundancy: Without backup mechanisms, any downtime can lead to a backlog of tasks, potentially causing system-wide issues when the service is restored.
Inflexibility: Scaling vertically by adding more resources to the machine is costly and has limits. At some point, it's just not feasible to keep adding resources to a single machine.
For example, consider a news website that sends out a daily digest email to its users. With a few hundred users, a single machine can manage this. However, as the user base grows to millions, sending out individualized emails within a small window becomes a considerable challenge. If the machine were to fail, millions could miss their daily digest, leading to a loss of trust and potential business implications.
Distributed Cron Jobs
Modern applications require a more robust, flexible, and scalable approach. This is where distributed cron jobs come into play.
The Distributed Cron Architecture
In our distributed approach, tasks are not managed and executed on a single machine. Instead, multiple machines or workers share the responsibility. A key component of this setup is a job scheduler that's aware of all tasks and can intelligently distribute them across all available workers.
System Architecture

Application Server:
Role: The application server is responsible for handling the creation of new jobs. It also immediately computes the next execution time based on the given cron expressions so it can be picked up by the Job Scheduler when due.
Job Scheduler:
Role: This is the most complicated component in our architecture. It schedules jobs that are due for execution.
Subcomponents:
Master: The master scheduler gets the count of pending jobs and distributes them among slave instances.
Slave: Slaves collect their assigned jobs based on instructions from the master, ensuring a unique job pull across the slaves.
Workers:
Role: Workers are responsible for retrieving and executing jobs.
Operation: Workers pull job messages dispatched by the Job Scheduler. These messages contain the data about the job to process.
Feedback Mechanism: After processing a job, workers update the database with the outcome.
Database (MongoDB):
Rationale: MongoDB was chosen due to its capability for horizontal scaling via sharding. Distributing data across several servers greatly enhances our application's write and read throughput. Additionally, it also supports secondary indexes, which can significantly speed up read operations.
Message Queue (Kafka):
Role: The message queue aids in decoupling our application's components, ensuring seamless communication and enhanced fault tolerance.
Why Kafka?: Kafka was chosen due to its capacity for horizontal scaling, enabling it to handle large volumes of messages efficiently. Furthermore, its distributed nature and ability to retain messages ensure high availability and resilience, crucial for our job execution flow.
Redis:
Redis, an in-memory data structure store, is renowned for its rapid performance and versatility.
Redis Integration: The job scheduler leverages Redis in two key ways:
Worker Registration: On startup, each instance of our job scheduler registers itself. This registration is vital as it ensures that jobs are distributed efficiently among all available instances. And deregisters when they die.
Master Election: Using Redis's distributed locking mechanism, one instance is elected as the master, ensuring a single distribution point.
Implementation Overview
Database Design: The system relies on two primary collections: the Job and the Job Schedule.
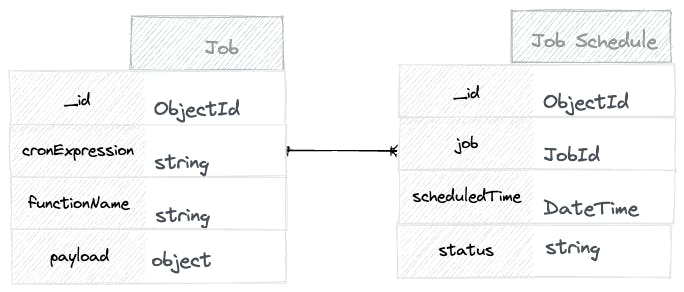
The Job collection contains detailed information about each task, including its cron expression.
The Job Schedule collection captures each time the job should run, determined by computing the associated job cron expression to get its next execution date.
Job Scheduling and Distribution: Periodically, the Master Job Scheduler probes the database for the total pending jobs count that are due for execution based on the current time. On getting the count, it is used to calculate pagination offsets for each available slave. This pagination information is then pushed to a dedicated Kafka topic, which the Slave Job Schedulers monitor. This process ensures each slave doesn't pull the same data.
When the Slave Job Scheduler receives a message, it fetches the pending tasks from the Job Schedule collection using the pagination offset data in the message. For every job returned, the slave sends it to another Kafka topic designated for worker consumption and computes the next execution time using the corn expression, then creates a new document in the Job Execution collection, which the Master Job Scheduler will access at the appropriate time.
Job Execution by Workers: These are the entities that actually do the work. When a worker pulls a job from their designated Kafka topic, the system identifies the appropriate local function to execute using the functionName string in the job data (message) and then runs it with the corresponding payload also extracted from the same data source. Upon completing the task, the worker updates the job's status in the database to reflect its new state.
Why This Solution Scales
Load Distribution: Tasks are divided and sent to various workers. If one worker goes down, others continue the work, ensuring no task remains unprocessed.
Dynamic Scalability: As demand grows, new workers can be added on the fly without disrupting the existing system.
Fault Tolerance: The system is built with mechanisms to prevent the double processing of tasks. If a worker encounters an issue or fails while processing a job, that specific job can either be reassigned to another worker or flagged for a retry attempt, ensuring robustness and resilience in operations.
Decoupled Components: Each part of the system (database, messaging queue, scheduler and worker) can scale independently based on its needs.
For our news website example, a distributed cron setup would mean sending out daily digests is divided among many workers. If one worker fails, the rest continue without a hitch. As the user base grows, we can simply add more workers to handle the increased load.
Conclusion
While traditional cron jobs serve their purpose for small-scale applications, the demands of modern, large-scale applications necessitate a more scalable and resilient approach. Distributed cron jobs, leveraging technologies like MongoDB, Redis, and Kafka, provide this scalability, ensuring that applications can meet user demands at any scale. Whether you're managing tasks for a few users or a few million, a distributed cron system ensures that every task is handled efficiently and reliably. For those who want a deeper dive into the details, the code implementation is available on GitHub.